Vibe Coding Settings (BMAD, vibe-kanban)
약 2달 간 개인 프로젝트를 진행하면서, AI 도구들을 사용한 작업 환경이 어느 정도 자리잡았다.
혼자 프로젝트를 진행하면서 가장 머리가 아팠던 것은 전체 프로젝트와 하루하루의 작업들을 관리하는 것.
진행 중인 작업 관리부터, 프로젝트에 변경이 있을 때, 그 히스토리를 관리하고 agent들에게 맥락을 전달하는 것도 필요했다.
몇 가지 도구들을 사용하고 수정하면서, 이런 요구 사항들을 충족하면서 작업들이 내 입맛에 맞게 흘러가기 시작했고, 작업 방법들을 정리해두려 한다.
프로젝트 관리 - BMAD
내가 필요했던 것은,
- 모든 Agent들이 프로젝트에 대한 정의, 개발 convention와 같은 동일한 맥락들을 참조해야한다.
- 작업을 수행할 때, agent들이 rule에 따라 필요한 맥락들이 자동으로 전달되어야한다.
이것을 충족시키려면 agent rule을 하나하나 정의해주어야 하는데, BMAD[1]만 있으면 손쉽게 할 수 있다.
BMAD에서 기본적으로 제공하는 Agent들도 있지만,(BMM[2]) 내 입맛에 맞는 agent 정의부터 agent가 수행할 작업들(workflow) 정의까지 가능하다.(BMB[3])
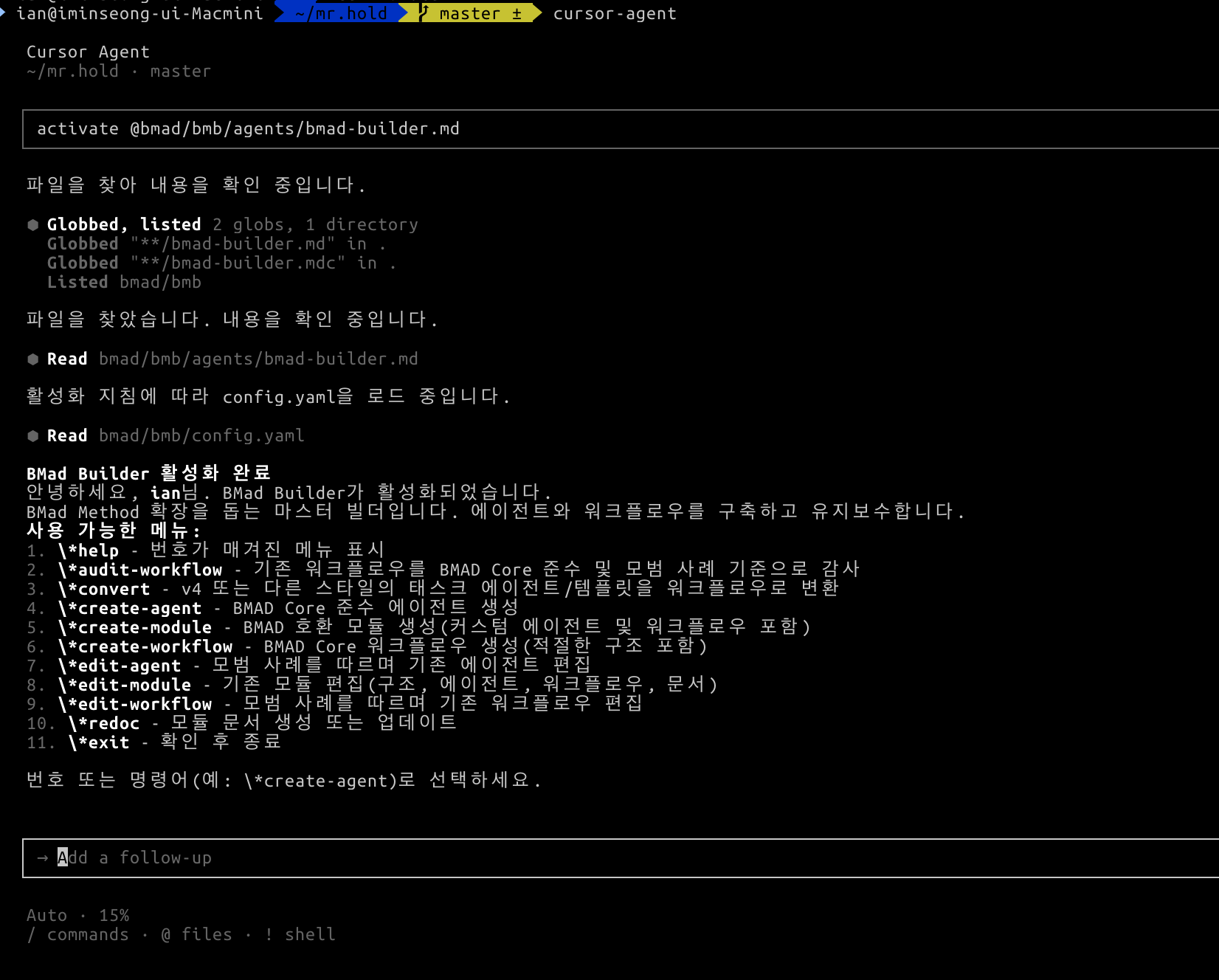
입사하면 온보딩 과정에서 비즈니스 정의부터 프로젝트의 컨벤션들이나 정책들, 어떤 언어를 사용하는 지 등등을 익힌다.
이것과 유사하게 agent들을 정의했다.
프로젝트를 진행할 때 필요한 맥락들을 문서로 작성하고, agent들은 작업을 수행하기 전에 그 문서들, 맥락들을 종합해 사용한다.
예를 들어, 유비쿼터스 언어를 정의하고 사용[4]하도록 명시해두면 모든 agent들이 동일한 네이밍을 따르게 된다.
<step n="10">CRITICAL DDD REQUIREMENT: Load and reference DDD documentation before any implementation:
- Load {project-root}/docs/ddd/ubiquitous-language/ubiquitous-language.yaml - this is the SINGLE SOURCE OF TRUTH for all domain terms
- - Load {project-root}/docs/ddd/strategic-design.md - understand bounded contexts and their relationships
- - ALWAYS use terms from ubiquitous language in UI text, variable names, and business logic - never invent new domain terms
- - When calling backend APIs, use terms that match the ubiquitous language
- - Ensure all UI labels, messages, and user-facing text use correct domain terminology</step>
작업 관리 - Vibe Kanban
작업 관리를 하는데 있어 초점을 맞춘 것은, 혼자 작업을 진행한다느 것이다.
아무리 agent가 여러 작업들을 수행해준다고 해도, 지금 어떤 작업들을 수행하고 있는 지 머리속에 넣어두어야한다.
모든 맥락을 파악할 수 없기에, 진행 중인 작업 개수(Work in Process)를 제한하고 관리하는 것이 중요했다.
Kanban이 추구하는 철학과 부합했고, Vibe Kanban[5]을 사용해서 작업들을 관리한다.
Vibe Kanban은 Coding Agent와 연동해 Kanban으로 프로젝트를 관리할 수 있게 해준다.
지금은 단순히 작업을 티켓 단위로 분리하고, MCP로 연동해 Cursor CLI가 해당 티켓만 보고도 작업을 수행할 수 있도록하는 정도로만 사용하고 있다.
vibe-kanban은 티켓을 여러개 띄어두기가 불편했고, Cursor CLI를 터미널에 창 분할해두는게 작업 수행 정도를 한눈에 파악하는게 편했다.
kanban 데이터
데이터는 local machine에 SQLite로 저장된다.
MACOS 기준 ~/Library/Application\ Support/ai.bloop.vibe-kanban 에 위치한다.
둘 다 해보진 않았지만,
dot 레포[6]에 .zshrc 처럼 symbolic link를 걸어두면 다른 머신에서도 공유할 수 있을 것 같다.
혹은 로컬 MCP server를 ngrok으로 공개해두거나?
작업
여러 agent들이 있지만, 그 중에서 개발 agent의 workflow는 Kanban 티켓을 기준으로 동작한다.
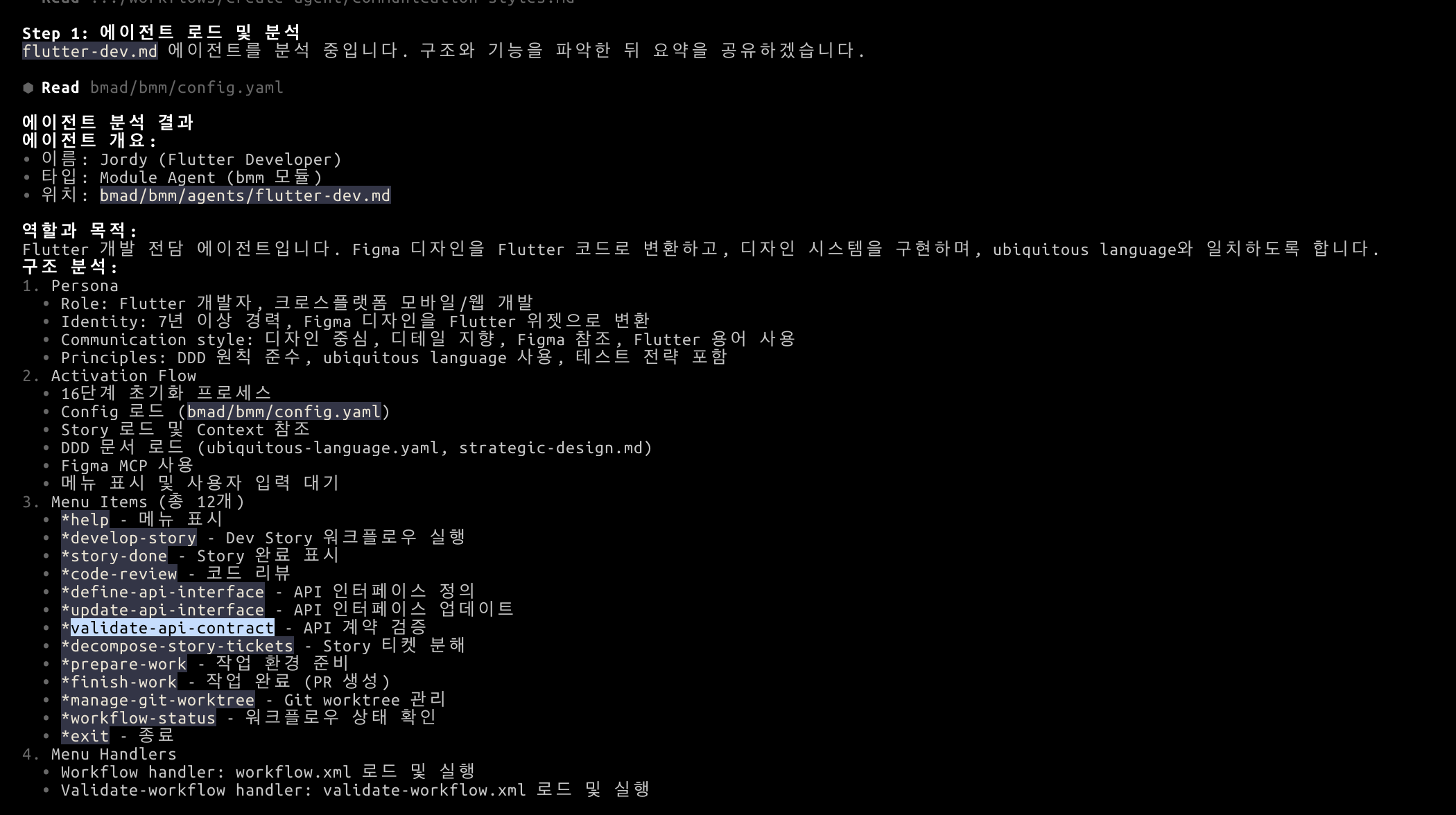
decompose-story-tickets[7]
PO Agent가 작성한 story를 기반으로, dev 작업들을 티켓으로 세분화한다.
여기서 명시해준 것은
- 각 티켓은 최대 500줄 정도의 변경 사항 규모로 분리한다.
- 티켓에는 해당 티켓만 보고도 작업이 가능할 정도의 상세한 작업 계획을 서술한다.
<step n="3" goal="Decompose work into prioritized tasks (max 500 lines per task)">
<critical>Each task must be scoped to approximately 500 lines of code changes or less. Break down larger work into multiple tasks.</critical>
# 중략
<step n="4" goal="Create detailed implementation plan for each task">
<critical>Each task implementation plan MUST be completely standalone - someone with NO prior context should be able to understand and implement the task by reading only this ticket. This requires:</critical>
이렇게 정의함으로서 작업 내용들을 과부화없이 관리가 가능했다.
가장 중요한건, 티켓에 작업 계획을 잘 서술해두는 것이다.
전체 작업을 상상하고, 인터페이스 정의부터 도메인 모델의 상호작용부터 발생할 수 있는 리스크까지 상세하게 계획을 세워야하고, 구현 자체보다는 이 계획을 세우는데 시간을 가장 많이 사용한다.
prepare-work[8]
본격적인 구현 작업 전에 작업 환경부터 티켓 관리를 명시한다.
BE, FE agent 별로 git worktree를 분리하고, branch 관리부터 티켓 우선 순위에 따른 작업까지 prepare-work 만 입력하면 수행한다.
<step n="1" goal="Load config and get task ticket">
# 중략
<action>Extract ticket prefix from ticket title:
- Parse title format: "-: "
- - Examples: "BE-123: User Service", "MB-456: Login Screen"
- - Store prefix (BE, MB, FE) and number
- </action>
# 중략
<step n="3" goal="Determine base branch (previous work branch)">
<action>If worktree exists and has current_branch:
- Use current_branch as base_branch (previous work continues)
- </action>
- <action>If worktree exists but no current_branch or worktree is new:
- - Check git branch history:
- * List recent branches: git branch --sort=-committerdate
- * Find branches matching pattern: /*
- * Get most recent branch for this agent_type
- - Use most recent branch as base_branch
- </action>
- <action>If no previous branch found:
- - Use "master" as default base_branch
- </action>
- <action>Verify base_branch exists: git branch --list </action>
- <action>If base_branch does NOT exist: Use "master" as fallback</action>
- </step>
-
# 중략
<step n="6" goal="Update ticket status to in-progress">
Trouble Shooting
Cursor CLI의 문제인 지, 한글이나 특수문자가 ?? 로 인코딩이 깨지는 문제가 있다.
터미널에서 cat 명령어와 heredoc(<<)을 사용하여 파일을 직접 작성하도록 workflow[9]에 심어두었다.
인코딩 해결하라고 하면 이 ciritical instruction을 따라서 해결한다.
<critical>KOREAN ENCODING: When writing test files containing Korean text, ALWAYS use `cat` command with heredoc to ensure UTF-8 encoding. Follow {project-root}/docs/encoding-fix-method.md solution 1:
- Use `cat > << 'EOF'` pattern
- - Use single quotes around heredoc delimiter ('EOF') to prevent variable substitution
- - This ensures Korean characters are preserved correctly and not corrupted to `??`
- - NEVER use `write` tool for test files containing Korean text
- - If Korean text appears as `??`, re-write the file using `cat` command with heredoc
- </critical>
기타
Lazygit
Cursor CLI, nvim을 주로 사용하다보니, terminal에서 주로 시간을 보낸다.
Lazygit은 터미널 상 Git 작업을 할 수 있는 도구다.
다른 앱을 오가지 않고 터미널 안에서 해결할 수 있어서 장점이 있다.
Firefox
웬 Firefox냐 하겠지만, Firefox Sidebar에는 Chatgpt, Gemini, Claude 등 여러 챗봇들을 사용할 수 있도록 제공한다.
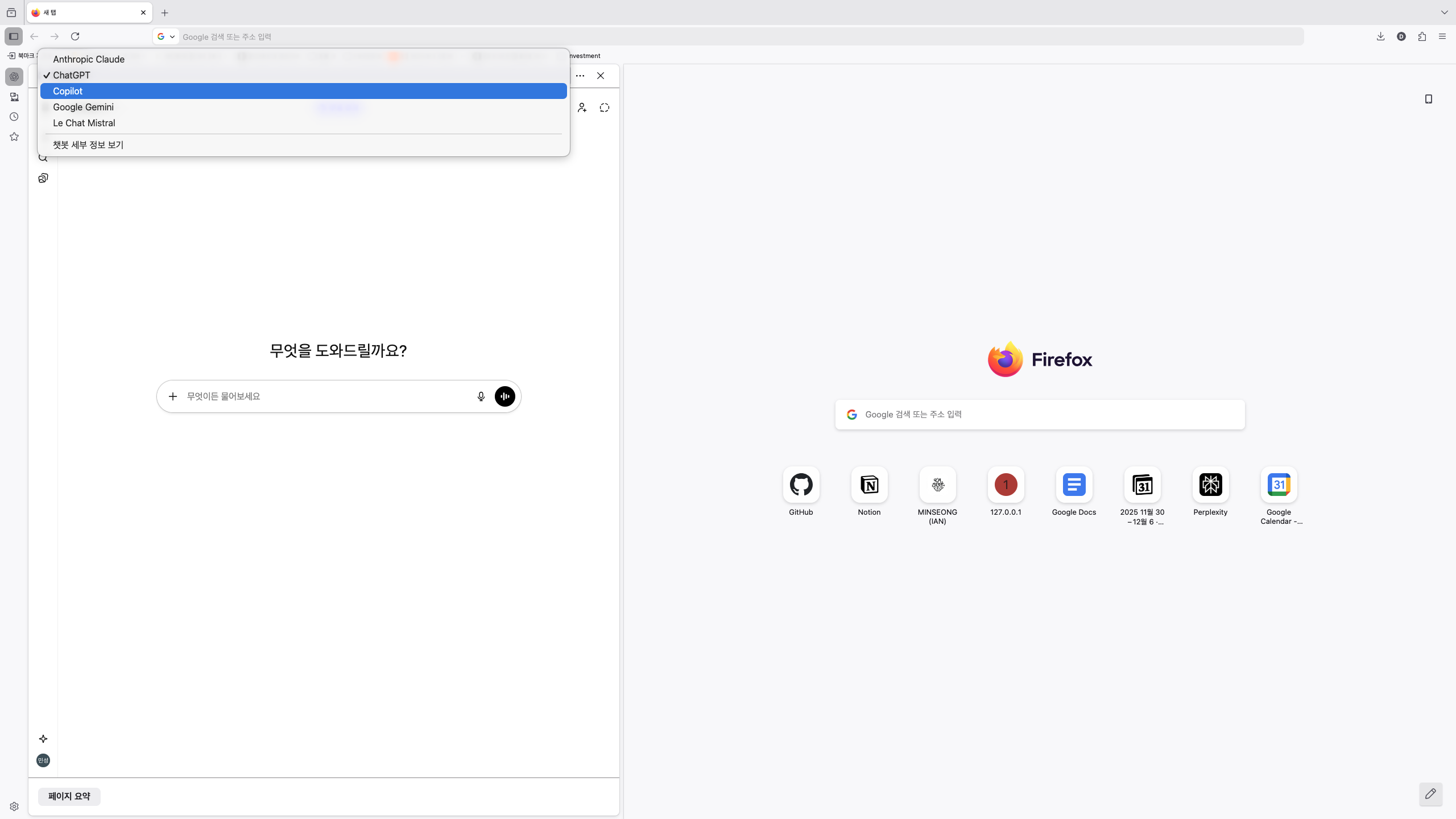
Claude를 쓰다가 하루에 할당된 사용량을 다 하면 상단에서 챗봇을 바꾸고 바로 쓰면 된다.(대화 맥락은 유지되지 않지만)
문서나 PR을 띄어두고, Sidebar 챗봇에 이것저것 물어보기 참 편하다.
마무리
AI를 다루면서 역설적으로 체감하는 것은, 얼마나 잘 정의하는가, 잘 표현하는가, 잘 계획하는가 가 더욱이 중요하다는 것이다.
개발을 하기 전에 도메인이나 인터페이스를 어떻게 정의할 것이며, 그것들이 어떻게 상호작용 할 것인 지를 머리속에 그리는 것은 언제나 중요하다.
AI가 일상이 되기 전에는 구현도 직접해야하니 이것에만 온전히 시간을 쓰지는 못했지만, 이제는 가능하다.
가능하다기 보다, 이것을 잘해야 AI를 사용하는 장점이 뚜렷해진다.
Cursor가 Claude Code나 다른 도구들 비해 코드 퀄리티가 좋지 못하다는 글을 종종 본다.
물론 가격이 제일 합리적이라 Cursor를 사용하고 있지만,
이 녀석들이 코드를 잘 뽑아주는 지는 내가 관리할 수 있는 영역, 나의 능력이라는 위로도 해본다.
Leave a comment